In this short tutorial, we will discuss how to install Apache Spark on the Ubuntu 22.04 LTS operating system. We will be using Apache Spark version 3.2.3. Apache Spark is commonly used as an analytics engine for machine learning and big data processing.
Apache Spark is an open-source unified analytics engine for large-scale data processing. Spark provides an interface for programming clusters with implicit data parallelism and fault tolerance. Originally developed at the University of California, Berkeley’s AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.
Apache Spark Installation On Ubuntu 22.04
Prerequisites
Before we start the installation process, there are several prerequisites that must be met so that the installation process can run smoothly. We will need to prepare any requirements as mention below :
- an Ubuntu 22.04 server system
- a non-root user with sudo privileges
- sufficient disk and good internet access
The Apache Spark Installation steps are as follow :
- Update and Upgrade System
- Install Java Runtime
- Download And Extract Apache Spark
- Testing Apache Spark
- Running Spark Shell
The explanation of the installation process will be discussed in several sub-chapters below.
1. Update and Upgrade System
The first step of Apache Spark installation is to update our local packages software. This task will cut down the installation time and it also helps prevent zero-day exploits against outdated software. We will use command line :
$ sudo apt update $ sudo apt -y full-upgrade
Output :
ramans@infodiginet:~$ sudo apt update [sudo] password for ramans: Hit:1 http://id.archive.ubuntu.com/ubuntu jammy InRelease Ign:2 http://download.webmin.com/download/repository sarge InRelease Hit:3 http://security.ubuntu.com/ubuntu jammy-security InRelease Hit:4 http://id.archive.ubuntu.com/ubuntu jammy-updates InRelease Hit:5 http://download.webmin.com/download/repository sarge Release Hit:7 http://id.archive.ubuntu.com/ubuntu jammy-backports InRelease Reading package lists... Done Building dependency tree... Done Reading state information... Done 9 packages can be upgraded. Run 'apt list --upgradable' to see them.
ramans@infodiginet:~$ sudo apt -y full-upgrade Reading package lists... Done Building dependency tree... Done Reading state information... Done Calculating upgrade... Done # # News about significant security updates, features and services will # appear here to raise awareness and perhaps tease /r/Linux ;) # Use 'pro config set apt_news=false' to hide this and future APT news. # The following NEW packages will be installed: linux-headers-5.15.0-56 linux-headers-5.15.0-56-generic linux-image-5.15.0-56-generic linux-modules-5.15.0-56-generic linux-modules-extra-5.15.0-56-generic The following packages will be upgraded: libfprint-2-2 libglib2.0-0 libglib2.0-bin libglib2.0-data libtiff5 linux-generic-hwe-22.04 linux-headers-generic-hwe-22.04 linux-image-generic-hwe-22.04 ubuntu-advantage-tools 9 upgraded, 5 newly installed, 0 to remove and 0 not upgraded. 4 standard LTS security updates Need to get 116 MB of archives. After this operation, 584 MB of additional disk space will be used. Get:1 http://id.archive.ubuntu.com/ubuntu jammy-updates/main amd64 libglib2.0-data all 2.72.4-0ubuntu1 [4.882 B] . . . update-initramfs: Generating /boot/initrd.img-5.15.0-56-generic /etc/kernel/postinst.d/zz-update-grub: Sourcing file `/etc/default/grub' Sourcing file `/etc/default/grub.d/init-select.cfg' Generating grub configuration file ... Found linux image: /boot/vmlinuz-5.15.0-56-generic Found initrd image: /boot/initrd.img-5.15.0-56-generic Found linux image: /boot/vmlinuz-5.15.0-53-generic Found initrd image: /boot/initrd.img-5.15.0-53-generic Found linux image: /boot/vmlinuz-5.15.0-25-generic Found initrd image: /boot/initrd.img-5.15.0-25-generic Found memtest86+ image: /boot/memtest86+.elf Found memtest86+ image: /boot/memtest86+.bin Warning: os-prober will not be executed to detect other bootable partitions. Systems on them will not be added to the GRUB boot configuration. Check GRUB_DISABLE_OS_PROBER documentation entry. done
2. Install Java Runtime
Apache Spark requires Java to run properly, so we have to install Java runtime first on our Ubuntu 22.04 system. In this tutorial we will user OpenJDK 17 to our system. To install OpenJDK 17 on Ubuntu 22.04 we will us following command line :
$ sudo apt install openjdk-17-jre-headless $ java --version
Output :
ramans@infodiginet:~$ sudo apt install openjdk-17-jre-headless [sudo] password for ramans: Reading package lists... Done Building dependency tree... Done Reading state information... Done The following packages were automatically installed and are no longer required: linux-headers-5.15.0-25 linux-headers-5.15.0-25-generic linux-image-5.15.0-25-generic linux-modules-5.15.0-25-generic linux-modules-extra-5.15.0-25-generic Use 'sudo apt autoremove' to remove them. The following additional packages will be installed: ca-certificates-java java-common Suggested packages: default-jre fonts-dejavu-extra fonts-ipafont-gothic fonts-ipafont-mincho fonts-wqy-microhei | fonts-wqy-zenhei The following NEW packages will be installed: ca-certificates-java java-common openjdk-17-jre-headless 0 upgraded, 3 newly installed, 0 to remove and 0 not upgraded. Need to get 48,2 MB of archives. After this operation, 191 MB of additional disk space will be used. Do you want to continue? [Y/n] Y . . . Processing triggers for man-db (2.10.2-1) ... Processing triggers for ca-certificates (20211016) ... Updating certificates in /etc/ssl/certs... 0 added, 0 removed; done. Running hooks in /etc/ca-certificates/update.d... done. done.
The we will verify it by using command line below.
ramans@infodiginet:~$ java --version openjdk 17.0.5 2022-10-18 OpenJDK Runtime Environment (build 17.0.5+8-Ubuntu-2ubuntu122.04) OpenJDK 64-Bit Server VM (build 17.0.5+8-Ubuntu-2ubuntu122.04, mixed mode, sharing)
3. Download And Extract Apache Spark
3.1. Download Spark Source file
At this stage, we will download and extract the Apache Spark source files. We will download Apache Spark version 3.2.3. We will use wget command line.
$ wget https://www.apache.org/dyn/closer.lua/spark/spark-3.2.3/spark-3.2.3-bin-hadoop3.2-scala2.13.tgz
Output :
ramans@infodiginet:~$ wget https://www.apache.org/dyn/closer.lua/spark/spark-3.2.3/spark-3.2.3-bin-hadoop3.2-scala2.13.tgz --2022-12-04 15:16:58-- https://www.apache.org/dyn/closer.lua/spark/spark-3.2.3/spark-3.2.3-bin-hadoop3.2-scala2.13.tgz Resolving www.apache.org (www.apache.org)... 151.101.2.132, 2a04:4e42::644 Connecting to www.apache.org (www.apache.org)|151.101.2.132|:443... connected. HTTP request sent, awaiting response... 200 OK Length: unspecified [text/html] Saving to: ‘spark-3.2.3-bin-hadoop3.2-scala2.13.tgz’ spark-3.2.3-bin-hadoop3.2-scal [ <=> ] 28,13K 167KB/s in 0,2s 2022-12-04 15:17:00 (167 KB/s) - ‘spark-3.2.3-bin-hadoop3.2-scala2.13.tgz’ saved [28807]
3.2. Extract Spark Tarball file
Then we will extract the Apache Spark tarball, by using tar command line as shown below :
$ tar xvf spark-3.2.3-bin-hadoop3.2.tgz
Output :
ramans@infodiginet:~$ tar xvf spark-3.2.3-bin-hadoop3.2.tgz spark-3.2.3-bin-hadoop3.2/ spark-3.2.3-bin-hadoop3.2/LICENSE spark-3.2.3-bin-hadoop3.2/NOTICE spark-3.2.3-bin-hadoop3.2/R/ spark-3.2.3-bin-hadoop3.2/R/lib/ spark-3.2.3-bin-hadoop3.2/R/lib/SparkR/ spark-3.2.3-bin-hadoop3.2/R/lib/SparkR/DESCRIPTION spark-3.2.3-bin-hadoop3.2/R/lib/SparkR/INDEX spark-3.2.3-bin-hadoop3.2/R/lib/SparkR/Meta/ . . . spark-3.2.3-bin-hadoop3.2/sbin/stop-worker.sh spark-3.2.3-bin-hadoop3.2/sbin/stop-workers.sh spark-3.2.3-bin-hadoop3.2/sbin/workers.sh spark-3.2.3-bin-hadoop3.2/yarn/ spark-3.2.3-bin-hadoop3.2/yarn/spark-3.2.3-yarn-shuffle.jar
3.3. Moving Spark Files
After file extracting was is completed done, then we will move spark engine file to /opt directory.
$sudo mv spark-3.2.3-bin-hadoop3.2 /opt/spark
3.4. Setting Spark Environment
The Spark environment configuration file is located at ~/bashrc file. At this file we will define the Spark binary files directory. We will append these text at the end of file.
$ vi ~/.bashsrc export SPARK_HOME=/opt/spark export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
Then activate the change by submitting command line :
$ source ~/.bashrc
4. Testing Apache Spark
4.1. Starting Stand Alone Master
At this stage, we already have Apache Spark ready to be tested. In this section, we will start up the Spark server and monitor it via the provided web interface. To start up stand alone master server we will submit command line :
$ ./start-master.sh
Output :
ramans@infodiginet:/opt/spark/sbin$ ./start-master.sh starting org.apache.spark.deploy.master.Master, logging to /opt/spark/logs/spark-ramans-org.apache.spark.deploy.master.Master-1-infodiginet.out
The service will be listening on port 8080, we will verify it by using command line :
$ sudo ss -tunelp | grep 8080
Output :
ramans@infodiginet:/opt/spark/sbin$ sudo ss -tunelp | grep 8080
tcp LISTEN 0 1 *:8080 *:* users:(("java",pid=13756,fd=250)) uid:1000 ino:71060 sk:c cgroup:/user.slice/user-1000.slice/user@1000.service/app.slice/app-org.gnome.Terminal.slice/vte-spawn-333a9ed1-a4f4-43a6-aeda-2f7c200fc66a.scope v6only:0 <->
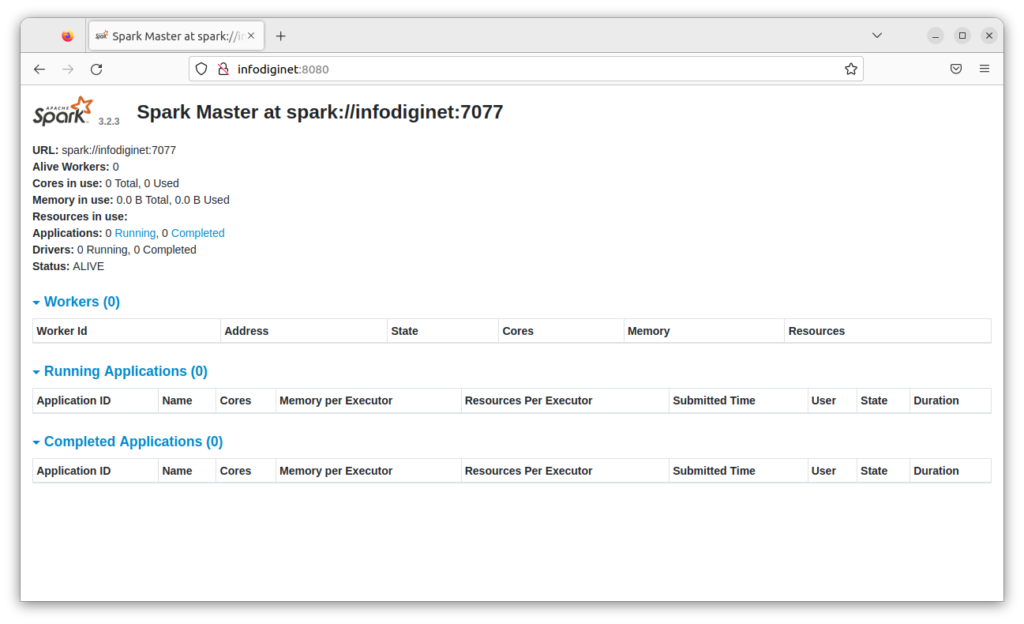
and we can also check it in the web interface as shown below.
4.2. Starting Spark Worker Process
We will start worker process by submitting command line :
$ ./start-worker.sh spark://infodiginet:7077
Output :
ramans@infodiginet:/opt/spark/sbin$ ./start-worker.sh spark://infodiginet:7077 starting org.apache.spark.deploy.worker.Worker, logging to /opt/spark/logs/spark-ramans-org.apache.spark.deploy.worker.Worker-1-infodiginet.out
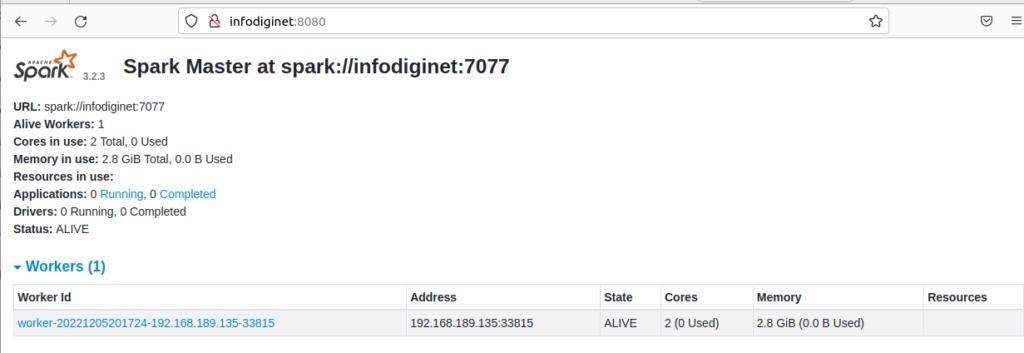
The above screenshot is shwoing a new worker process.
5. Running Spark Shell
If we want to access Spark shell, we can use command line :
$ /opt/spark/bin/spark-shell
Output :
ramans@infodiginet:/opt/spark/sbin$ /opt/spark/bin/spark-shell
22/12/05 20:27:37 WARN Utils: Your hostname, infodiginet resolves to a loopback address: 127.0.1.1; using 192.168.189.135 instead (on interface ens33)
22/12/05 20:27:37 WARN Utils: Set SPARK_LOCAL_IP if you need to bind to another address
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.properties
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
22/12/05 20:27:45 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
java.lang.IllegalAccessError: class org.apache.spark.storage.StorageUtils$ (in unnamed module @0x62bd2070) cannot access class sun.nio.ch.DirectBuffer (in module java.base) because module java.base does not export sun.nio.ch to unnamed module @0x62bd2070
at org.apache.spark.storage.StorageUtils$.<init>(StorageUtils.scala:213)
at org.apache.spark.storage.StorageUtils$.<clinit>(StorageUtils.scala)
at org.apache.spark.storage.BlockManagerMasterEndpoint.<init>(BlockManagerMasterEndpoint.scala:110)
at org.apache.spark.SparkEnv$.$anonfun$create$9(SparkEnv.scala:348)
at org.apache.spark.SparkEnv$.registerOrLookupEndpoint$1(SparkEnv.scala:287)
at org.apache.spark.SparkEnv$.create(SparkEnv.scala:336)
at org.apache.spark.SparkEnv$.createDriverEnv(SparkEnv.scala:191)
at org.apache.spark.SparkContext.createSparkEnv(SparkContext.scala:277)
at org.apache.spark.SparkContext.<init>(SparkContext.scala:460)
at org.apache.spark.SparkContext$.getOrCreate(SparkContext.scala:2690)
at org.apache.spark.sql.SparkSession$Builder.$anonfun$getOrCreate$2(SparkSession.scala:949)
at scala.Option.getOrElse(Option.scala:189)
at org.apache.spark.sql.SparkSession$Builder.getOrCreate(SparkSession.scala:943)
at org.apache.spark.repl.Main$.createSparkSession(Main.scala:106)
... 55 elided
<console>:14: error: not found: value spark
import spark.implicits._
^
<console>:14: error: not found: value spark
import spark.sql
^
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 3.2.3
/_/
Using Scala version 2.12.15 (OpenJDK 64-Bit Server VM, Java 17.0.5)
Type in expressions to have them evaluated.
Type :help for more information.
scala>
Conclusion
In this short tutorial, we have learned how to install Apache Spark on Ubuntu 22.04 LTS operating system. We have used Spark version 3.2.3 and tried some commands to start master and worker. I hope this tutorial will be helpful.

